고정 헤더 영역
상세 컨텐츠
본문
출시된 지 8년이 지난 Nvidia Tesla P40 GPU를 장착하여 대용량 VRAM을 저렴하게 확보하되, vLLM의 병렬 연산 기능을 활용하여, P40의 느린 속도를 보완하여 쓸만한 AI 시스템을 구성한 기록이다.
(AI용 가성비 GPU P40 소개 : https://kmuh.tistory.com/98)
vLLM은 병렬 연산으로 복수의 GPU에서 최대 성능을 끌어내는 데 특화된 AI 플랫폼이다.
리눅스만 지원되며 윈도우는 지원되지 않는다.
vLLM은 구형 GPU에 대한 지원은 상당히 취약하며, 단종된 지 오래된 파스칼 아키텍처인 P40은 정식 지원되지 않는다.
하지만, 파스칼 아키텍처는 Nvidia 드라이버, CUDA, PyTorch등 대부분의 AI 생태계 핵심 구성 요소에서 여전히 정식 지원되고 있으므로, vLLM에 호환 패치만 적용하면 실행할 수 있다..
이 포스트에서는 파스칼 아키텍처 호환 패치가 적용된 비공식 vLLM 패키지를 설치한다.
(파스칼 호환 패치된 vLLM : https://github.com/sasha0552/pascal-pkgs-ci)
우선, vLLM의 병렬 처리 기능을 사용하려면 GPU의 숫자가 2의 배수(2/4/8개)이어야 한다.
시스템에 장착된 GPU 수량이 vLLM의 요구 수량과 맞지 않다면, GPU를 추가 장착하거나, 'CUDA_VISIBLE_DEVICES' 환경변수를 사용해서 vLLM에 노출되는 GPU 수량을 제한해서 요구 수량에 맞추어야 한다.
이 포스트는 다음 조건으로 작성되었다.
- P40 GPU 4개
- CPU에 내장된 iGPU로 화면 출력
이 포스트에 나온 실행 옵션 중에서 다음 옵션은 각자의 시스템 사양에 맞게 변경해야 한다.
- GPU 4개 병렬 연산 옵션 (-tp 4)
- GPU 수량이 4개 이상일 때만 필요한 옵션 (--disable-custom-all-reduce)
- GPU VRAM 100%를 vLLM에게 할당하는 옵션 (--gpu-memory-utilization 1)
이 포스트에서 설명한 설치 절차는 리눅스 배포판 '우분투 22.04 LTS' 혹은 '우분투 24.04 LTS' 기준 이다.
(이외 다른 데비안 혹은 파생 배포판에서도 가능할 것으로 추정된다.)
<!!> Nvidia 드라이버는 최신 버전이 아니라, CUDA와 호환되는 버전을 설치해야 함. <!!>
현재 시점(2025년 4월) 기준 vLLM은 CUDA 12.4를 사용한다.
그래서, CUDA 12.4와 호환성이 가장 좋다고 생각되는 Nvidia 드라이버 버전 550를 설치한다.
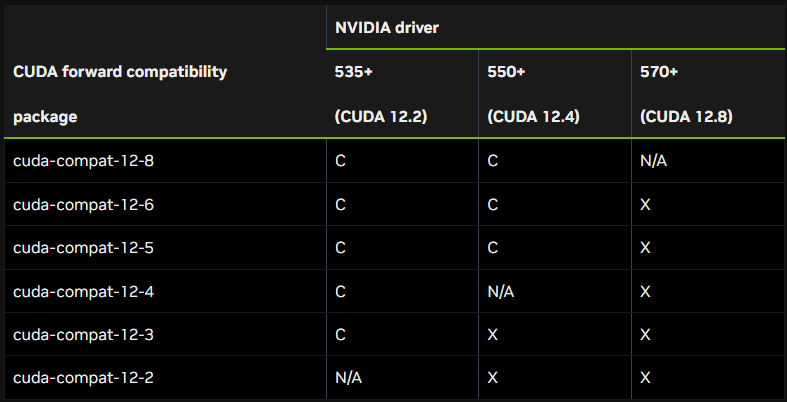
Nvidia 드라이버 550 버전 설치
$ sudo apt update
$ sudo apt upgrade
$ sudo apt dist-upgrade
$ sudo apt install nvidia-driver-550
$ sudo reboot # 재부팅
$ nvidia-smi # 실행 화면에 GPU가 보여야 설치가 제대로 된 것이다.
(nvidia-smi 실행 화면 예제 : https://kmuh.tistory.com/196)
멀티 GPU간 P2P 토폴로지 확인. (실행 옵션을 결정할 때 필요함.)
$ nvidia-smi topo -p2p n
실행 화면에 NS(Not Supported : 미지원)가 주르륵 나온다면 P2P가 지원되지 않는다는 의미이므로, 실행 옵션에서 'NCCL_P2P_DISABLE' 환경변수를 설정하여 P2P를 비활성화 해야한다.
(NS는 안 나오고 다른 값이 출력된다면 공식 문서를 참조하여 P2P 지원 레벨에 맞게 옵션을 조절해야 함.)
각종 호환성(버전 충돌) 문제를 피하기 위해서 docker 형식으로 설치.
$ sudo apt install docker.io # 우선 docker 설치
$ sudo usermod -a -G docker $USER # docker 관련 권한 부여.
(반드시, 재부팅 혹은 '로그아웃 후 로그인'을 해 줘야 변경된 docker 관련 권한이 적용됨.)
이제 nvidia-container-toolkit (docker용 nvidia 런타임) 설치해야 한다.
구체적인 설치 방법은 다음 링크에 나와 있다.
https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/latest/install-guide.html
우선 curl이 설치되어 있어야 한다.
sudo apt install curl
이후 링크에 나와있는 설치 명령어를 실행한다.
curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg \
&& curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list | \
sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \
sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
sudo apt-get update
sudo apt-get install -y nvidia-container-toolkit
'/etc/docker/daemon.json'에 다음 내용 추가한다. (파일이 없으면 생성)
{
"runtimes": {
"nvidia": {
"path": "nvidia-container-runtime",
"runtimeArgs": []
}
},
"default-runtime": "nvidia"
}
반드시 재부팅을 해야만 변경 사항이 적용되어 이후 실행 과정에서 에러가 발생하지 않는다..
vLLM 설치 (파스칼 아키텍처 호환 패치된 비공식 버전)
http://ghcr.io/sasha0552/vllm 에 접속해서 업로드된 최신 버전을 설치해 준다.
docker pull ghcr.io/sasha0552/vllm:v0.8.1
vLLM 도커 이미지 정상 작동 여부를 테스트하기 위해서 아주 작은 AI모델을 실행.
docker run --runtime nvidia --gpus all --ipc=host -p 18888:18888 -v ~/.cache/huggingface:/root/.cache/huggingface -e NCCL_P2P_DISABLE=1 ghcr.io/sasha0552/vllm:v0.8.1 --model facebook/opt-125m --disable-custom-all-reduce --enforce-eager -tp 4(충돌을 피하기 위해서 잘 안 쓰이는 18888번 포트를 사용했으나, 원한다면 다른 포트를 사용해도 됨.)
다음 메세지가 나오면 vLLM이 정상 작동하는 것이다.
INFO: Application startup complete.
(에러가 발생한다면 재부팅 후 다시 실행해 본다.)
실행 옵션 설명
--runtime nvidia : nvidia-container-toolkit을 사용한다고 지정
--gpus all : 장착된 모든 Nvidia GPU를 docker에게 노출.
(노출 수량을 제한해야 한다면 'CUDA_VISIBLE_DEVICES' 환경변수를 사용.)
--ipc=host 혹은 --shm-size=<용량> 둘 중 하나만 사용 가능
-e : 환경변수 설정 옵션.
-e NCCL_P2P_DISABLE=1 : 멀티 GPU에서 P2P가 지원되지 않으면 비활성화 시키는 환경변수 설정.
-e OMP_NUM_THREADS=4 : CPU 코어 수량에 맞게 적절하게 설정.
8코어 CPU이라서 절반인 4개로 설정.
(실행 화면 경고에 따라서 추가한 옵션임. 경고 안 뜨면 굳이 설정할 필요 없음.)
--max-model-len : 컨텍스트 길이 제한. AI 모델 자체는 VRAM에 다 들어가는 상황에서 추가로 컨텍스트가 VRAM 용량을 초과할 때, 이 옵션을 사용해서 컨텍스트 길이를 제한하면 에러가 해결된다.
--disable-custom-all-reduce : GPU가 4개(혹은 그 이상)일 때만 필요한 옵션.
--enforce-eager : vLLM이 필요한 VRAM 용량을 선제적으로 점유해서 메모리 부족 가능성을 줄이는 옵션.
--gpu-memory-utilization : 모델 실행 시 사용할 GPU 메모리 비율. 기본값 0.9. CPU 내장 GPU로 화면 출력을 한다면 1로 설정해서 VRAM 활용도를 높이면 됨.
-tp : 병렬 연산에 사용될 GPU 수량을 지정하면 됨.
--served_model_name : 모델 ID를 명확하게 지정하고자 할 때 사용.
facebook/opt-125m : 용량이 아주 작아서 금방 다운로드 되는 소형 모델.
vLLM 정상 작동 여부를 테스트하는 용도로 적합하다.
개인적으로 vLLM에서 전통적으로 지원되는 GPTQ 포맷보다는 MS윈도우에서 많이 쓰던 GGUF 포맷을 선호.
이 포스트에서는 GGUF 위주로 진행한다.
(vLLM이 최근에서야 GGUF 포맷을 지원하기 시작해서, 최적화가 덜 되었고, 아직까지 분할된 GGUF 파일을 지원하지 않으므로, 다운로드 받은 후 수동으로 병합해 줘야 하는 등 한계가 있으니 유의.
GGUF 파일 병합 : https://kmuh.tistory.com/125)
전통적인 GPTQ는 --model 옵션에서 허깅페이스 사이트의 모델 이름만 지정하면, 자동으로 다운로드 되는 점은 편리하지만, 다운로드 진행 상황을 알 수 없어서 용량이 큰 모델의 첫 실행을 기다리는 동안 제대로 진행되고 있는 지 확인할 방법이 없다.
반면 GGUF는 수동으로 다운로드 받고, 분할된 경우 병합시켜주는 등의 번거로움이 있지만, 웹브라우저에서 다운로드 진행상황을 확인할 수 있다는 점은 진입장벽을 맞춰준다.
다운로드 받은 GGUF파일을 vLLM 도커 이미지가 찾을 수 있게 하려면, -v 옵션으로 GGUF 파일이 위치한 디렉토리를 매핑시켜줘야 한다.
(아래 예제에서는 GGUF파일이 위치한 실제 디렉토리를 '/models'로 매핑함)
$ docker run --runtime nvidia --gpus all --ipc=host -p 18888:18888 -v <GGUF파일이 위치한 디렉토리>:/models -e NCCL_P2P_DISABLE=1 -e OMP_NUM_THREADS=4 -e NO_LOG_ON_IDLE=1 -e VLLM_DO_NOT_TRACK= 1 ghcr.io/sasha0552/vllm:v0.8.1 --model /models/<GGUF파일 이름> --port 18888 --disable-custom-all-reduce --enforce-eager --gpu-memory-utilization 1 -tp 4
Llama 3.3 70B GGUF 모델을 사용할 때, 다음과 같은 에러가 발생한다.
ValueError: No supported config format found in <모델명>
GGUF 파일이 위치한 디렉토리에 다음과 같이 config.json을 생성해주면 해결된다.
{
"model_type": "llama"
}
vLLM의 병렬 연산을 이용해서 Llama 3.3 70B 모델을 실행하니 속도가 12 t/s 이다.
전력 소모량, 발열 제어, 팬소음등의 이유로 동작 클럭을 최고 클럭의 60%정도(923MHz)로 설정하면 전력소모량은 120W 정도에 실행 속도는 10 t/s 정도 나온다.
(일상적인 사용에 답답함을 느끼지 않는 속도의 기준선이 대개 10 t/s 정도이다.)
각자 상황에 맞게 전력소모량과 동작 클럭을 적절하게 조절해서 사용하면 될 듯하다.
- 전력 소모량 조절 : nvidia -pl <전력소모량>
- 동작 클럭 조절 : nvidia -ad <메모리 클럭>,<GPU 클럭> (쉼표 ',' 앞뒤에 공백이 없어야 함.)
(GPU 온도 자동 관리 : https://kmuh.tistory.com/137)
결론적으로 저렴한 구형 P40과 vLLM의 병렬 연산 기능을 조합하면 70B 모델을 답답하지 않게 사용할 수 있는 가성비 시스템을 구성할 수 있다는 것을 확인했다.
(다만, 금전적 절약을 한 대신에 '수많은 삽질'이라는 노동력 투입이 필요하다.)
'AI' 카테고리의 다른 글
| Chain of Draft - 초안의 사슬 (0) | 2025.04.03 |
|---|---|
| AI + MCP = 자동 매매 시스템? (4) | 2025.03.31 |
| Ollama 환경변수 (0) | 2025.03.29 |
| Qwen2.5-Coder 사용기 (0) | 2025.03.28 |
| 쿼드 GPU로 VRAM 96GB 확보 (4) | 2025.03.26 |




